If you were asked to draw as accurate a picture of a bicycle as possible, the end result would most likely be a far cry from reality. If you tried to name the different parts of words, things would probably not be much easier. Neither skill is of much use in everyday life, but if you want to build any sort of functional mechanism, you have to know where everything needs to go, right down to the last nut and bolt.
Born as a result of academic research, Lingsoft was founded in 1986, when language technology pioneers Kimmo Koskenniemi and Fred Karlsson realised that they had created something unique: a method that could be used to model words language-independently. Thanks to language structure analysis, machines can now process even an inflection-rich language such as Finnish. In this digital age, being able to find the necessary information in a veritable deluge of text has become increasingly important, thus making language structure analysis more timely than ever.
The challenge: structurally rich languages
Technologies developed for English are often unsuitable for the machine analysis of Finnish materials. The reason for this is obvious: According to Koskenniemi, it is theoretically possible to decline a single Finnish noun in roughly 2,000 different ways. Adjectives can be declined in 6,000 different ways and the conjugation of verbs can take 12,000 different forms. If the Finnish language actually used every form of every word, the number of words in the language would amount to roughly 10²⁴ words, i.e. the same number of stars estimated to be in the universe. Lingsoft's language technology solution is based on language structure analysis, which makes the machine analysis of free-form, unstructured texts possible, regardless of the number of inflections.
Because structure analysis was developed at a time when computing power was nothing compared to what we have today, the method had to be as economical as possible. The method was also designed to be language-independent, which ensured that the knowledge imparted by these two Finns in their dissertations would find its way out into the world, all the way to Silicon Valley.
Lingsoft dives deeper into language
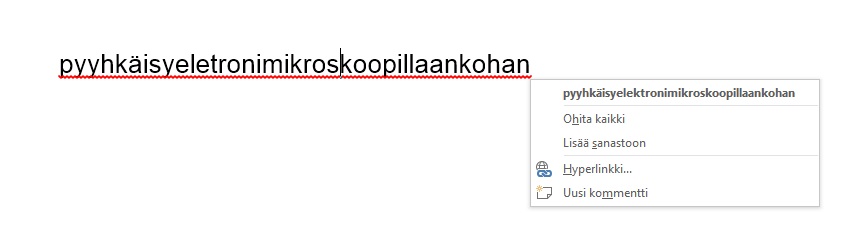
To put it in simple terms, language structure analysis involves training a machine in word inflection and formation. Once this is done, the machine will be able to recognise a given word in all of its inflected forms within a free-form text, restore the root form of the word, perform a grammatical analysis and recognise compound word boundaries. Then for example Word's proofreading function – which is also based on Lingsoft's structure analysis – would see that a completely invented compound word such as pyyhkäisyeletronimikroskoopillaankaankohan was missing one 'k'. This error would be hard to spot for the human eye, but with structure analysis, the machine can break the word down into its constituent components and find the error.
Interpreting ambiguity
Over half of all Finnish words can be interpreted in multiple ways, such as the word alusta. The word might refer to, for example, the elative singular form of the noun alku (start, beginning) or the second-person singular imperative active form of the verb alustaa (to introduce, to format). In practice, not every interpretation can be used in every context. Our analysis can be used to eliminate the interpretations that are not suitable for a given situation.
"<alusta>"
"alku" N ELA SG
"alusta" N NOM SG
"alustaa" V PRES ACT NEG
"alustaa" V IMPV ACT SG2
"alustaa" V IMPV ACT NEG SG
"alunen" N PTV SG
"alus" N PTV SG
Depending on the solution, the elimination of interpretations that do not fit in a given context can result in better proofreading correction suggestions, effective indexing or machine translation that understands context.
Language structure analysis remains the cornerstone of Lingsoft's solutions, from simple text search improvements to highly demanding text mining processes. It also supplements our newer solutions that are based on machine learning, such as speech recognition.